第六章 并发性
本章包括:
- 并发性的重要性
- 并发与并行
- Nim语言的Thread 线程
- 使用正则表达式和其他方法对数据进行高级分析
- 并行分析大型数据集
每个计算机程序执行一个或多个计算。这些计算通常按顺序执行。也就是说,当前计算必须在下一个计算开始之前完成。例如,考虑一个简单的计算(2+2)4,其中必须首先计算加法得到 4 ,然后再进行乘法得到 16 。在该示例中,依次执行计算并发允许多个计算进行,而无需等待所有其他计算完成。这种计算形式在许多情况下都很有用。一个示例是输入/输出应用程序,如您在第3章*中开发的聊天应用程序。当按顺序执行时,此类应用程序将浪费时间等待输入或输出操作完成。并发性允许将此时间用于其他任务,从而大大减少应用程序的执行时间。
Nim提供了许多内置的并发功能。其中包括 Futures 和 await 形式的异步I/O功能,以及用于创建新线程的 spawn 等。您已经看到了 第3章 中使用的一些。
Nim中的并发性仍在不断发展,这意味着本章中描述的功能可能会发生变化或被新的更健壮的功能所取代。但是Nim中并发的核心概念应该保持不变,本章将学习的内容也适用于其他编程语言。
除了向您展示Nim的并发特性之外,本章还将带领您完成一个简单解析器的实现,它将向您展示创建解析器的不同方法。然后,本章将通过优化解析器来结束,以便它是并发的,并且可以在多个CPU内核上并行运行。
6.1 并发与并行
如今,几乎所有操作系统都支持多任务处理,即在一定时间内执行多个任务的能力。任务通常称为进程,它是正在执行的计算机程序的实例。每个CPU一次只执行一个进程。多任务允许操作系统改变当前在CPU上执行的进程,而不必等待进程完成其执行图6.1显示了如何在多任务操作系统上同时执行两个进程。
图6.1.两个过程的并发执行
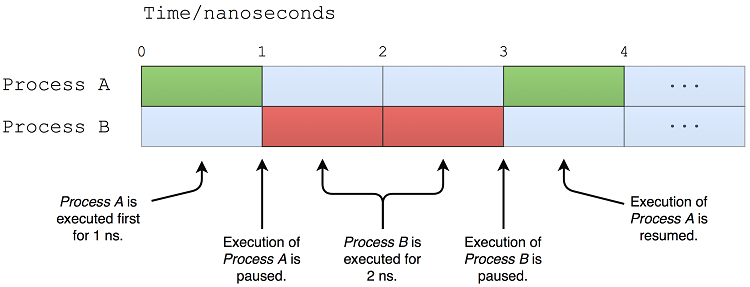
由于CPU速度极快,进程A可以执行1纳秒,然后进程B可以执行2纳秒,然后过程A可以执行另一纳秒。这给人一种同时执行多个进程的印象。但这不可能发生,因为CPU一次只能执行一条指令。这种同时执行多个进程的明显现象称为并发。
近年来,多核CPU变得流行起来。这些类型的CPU由两个或多个独立的单元组成,它们可以同时运行多个指令。这允许多任务操作系统同时并行运行两个或多个进程图6.2显示了如何在双核CPU上并行执行两个进程。
Figure 6.2. 并行执行两个进程
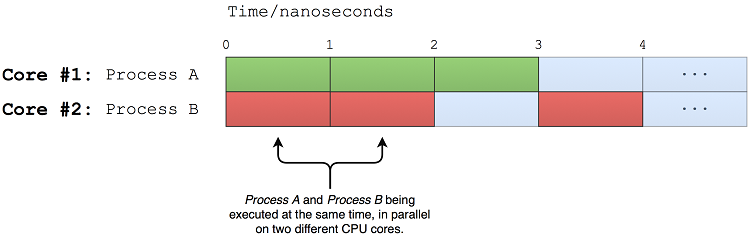
与单核CPU相反,双核CPU实际上可以同时执行两个进程。这种类型的执行被称为并行,它只能在多个物理CPU上实现。请记住,尽管并发和并行之间有明显的相似之处,但两者并不相同。
除了进程之外,操作系统还管理线程Thread的执行。线程是进程的一个组件,同一进程中可以存在多个线程。它可以像进程一样并发或并行执行,尽管与进程不同,线程之间共享内存等资源。
为了充分利用多核CPU的能力,CPU密集型计算必须并行化。这可以通过使用多个进程来实现,尽管线程更适合于需要共享大量数据的计算。
您在第3章中看到的异步等待是严格并发的。因为异步代码总是在单个线程上运行,所以它不是并行的。这意味着它目前无法使用多核CPU的全部功能。
[备注]:并行异步等待 Nim的未来版本很可能包括并行异步等待。
与异步等待不同, spawn 是并行的,专门为CPU密集型计算而设计,可以从在多核CPU上执行中受益。
[备注] 其他编程语言中的并行性 一些编程语言(如Python和Ruby)不支持线程级并行,因为它们的解释器中存在全局解释器锁。这防止了使用线程的应用程序使用多核CPU的全部功能。有一些方法可以克服这种限制,但它们需要使用不像线程那样灵活的进程
6.2在Nim中使用线程
既然您已经了解了并发和并行之间的区别,那么就可以学习如何在Nim中使用线程了。
在Nim中,有两个模块用于处理线程。 threads 模块[[19]](#ftn.d5e6428)公开了手动创建线程的能力,使用此方法创建的线程立即执行指定的过程,并在该过程的运行时间内运行。还有实现线程池的 threadpool 模块[[20]](#ftn.d5e6432),它公开了将指定过程添加到线程池的任务队列的 spawn 。 spawn 过程的行为并不意味着它将立即在单独的线程中运行。线程的创建完全由线程池管理。
接下来的部分将向您介绍两个不同的线程模块,因此不要对上一段中介绍的新术语感到不知所措。
6.2.1 threads 线程模块和GC安全
在本节中,我将查看 threads 模块。但在开始之前,我必须解释Nim中线程的工作方式,特别是您将了解Nim中的垃圾收集器安全性。Nim和大多数其他编程语言中线程的工作方式有一个非常重要的区别。Nim的每个线程都有自己的独立内存堆。线程之间的内存共享受到限制,这有助于防止竞争条件并提高效率。
由于每个线程都有自己的垃圾收集器,因此效率得到了提高。在共享内存的线程中,执行其他业务代码时, 需要在垃圾收集器暂停所有线程。这可能会给应用程序添加有问题的暂停。
让我向您展示这个线程模型在实践中是如何工作的清单6.1显示了一个未编译的代码示例。
清单6.1.使用 Thread 更改全局变量。
var data = "Hello World" # <1>
proc showData() {.thread.} = # <2>
echo(data) # <3>
var thread: Thread[void] # <4>
createThread[void](thread, showData) # <4>
joinThread(thread) # <6>
<1> 定义一个新的全局变量
data并赋值文本为 "Hello World"<2> 定义一个新的过程,将在新线程中执行. 用{.thread.} 编译指示标识。
<3> 尝试显示
data变量的值。<4> 定义一个变量来存储新线程,泛型参数表示线程过程采用的参数类型。在这种情况下,
void表示过程不接受参数<5>
createThread过程在新线程中执行指定的过程。<6> 等待
thread线程结束。[备注]
threads模块threads模块是system系统模块隐式导入的一部分,因此你不用再导入。
这个示例说明了Nim中的 GC安全 机制所不允许的内容,稍后您将看到如何修复该示例以便进行编译。将清单6.1中的代码保存为 listing01.nim ,然后执行 nim c--threads:on listing01.nim 以编译它。 --threads:on 标志是启用线程支持所必需的。您应该看到一个类似于清单6.2中的错误。
清单6.2. 清单6.1的编译输出
listing01.nim(3, 6) Error: 'showData' is not GC-safe as it accesses 'data' which is a global using GC'ed memory
该错误很好地描述了问题。全局变量 data 已在主线程中创建,因此它属于主线程的内存。 showData 线程无法访问另一个线程的内存,如果它试图访问,则编译器不认为它是GC安全的。编译器拒绝执行GC不安全的线程。
只要一个过程不访问任何包含垃圾回收内存的全局变量,编译器就认为它是GC安全的。赋值或任何类型的变异也算作访问,是不允许的。垃圾回收内存包括(但不限于)以下类型的变量:
* string
* seq[T]
* ref T
还有其他在线程之间共享内存的方式是GC安全的。例如,可以将 data 的内容作为参数之一传递给 showData 清单6.3显示了如何将数据作为参数传递给线程,清单6.3和清单6.1之间的差异以粗体显示(两个星直间的参数)。
清单6.3.将数据安全地传递给线程
var data = "Hello World"
proc showData(**param: string**) {.thread.} = # <1>
echo(**param**) # <2>
var thread: Thread[ **string** ] # <3>
createThread[ **string** ](thread, showData, **data**) # <4>
joinThread(thread)
<1> 这次在过程定义中指定了
string类型的参数<2> 过程参数传递给
echo,而不是全局变量data。 <3>void已被string替换,以表示showData过程采用的参数类型 <4>data全局变量被传递给createThread过程,该过程将将其传递给showData。
保存 清单 6.3 的代码为 listing2.nim 文件, 然后运行命令编译 nim c -r --threads:on listing2.nim 。 编译成功后运行会显示 "Hello World"。
createThread 过程只能将一个变量传递给它正在创建的线程。为了将多个单独的数据段传递给线程,必须定义一个新类型来保存数据。下面的列表显示了如何做到这一点。
type
ThreadData = object
param: string
param2: int
var data = "Hello World"
proc showData(**data: ThreadData**) {.thread.} =
echo(**data.param, data.param2**)
var thread: Thread[**ThreadData**]
createThread[**ThreadData**](thread, showData, **ThreadData(param: data, param2: 10)**)
joinThread(thread)
线程的执行
到目前为止,上面清单中创建的线程还没有做太多。让我们来检查这些线程的执行情况,看看当同时创建两个线程并被指示显示几行文本时会发生什么情况——在下面的示例中,显示了两个整数序列。
清单6.4.执行多个线程
var data = "Hello World"
proc countData(param: string) {.thread.} =
for i in 0 .. <param.len: # <1>
stdout.write($i) # <2>
echo() # <3>
var threads: array[2, Thread[string]] # <4>
createThread[string](threads[0], countData, data) # <5>
createThread[string](threads[1], countData, data) # <5>
joinThreads(threads) # <6>
<1> 循环迭代从0到参数
param的长度减去1。<2> 显示当前迭代计数器而不显示新行字符。
<3> 运行到下一行
<4> 这次有两个线程,它们存储在一个数组中。
<5> 创建一个线程并将其分配给
threads数组中的一个元素。<6> 等待所有线程完成。
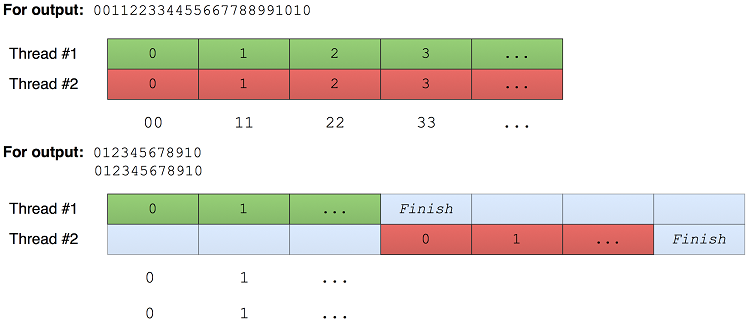
保存清单6.4的代码为 listing3.nim ,然后编译运行,清单6.5显示了大多数情况的输出,清单6.6显示了有时的输出。
清单6.5.执行清单6.4中的代码时的第一个可能输出:
001122334455667788991010
清单6.6.执行清单6.4中的代码时的第二个可能输出
012345678910
012345678910
线程的执行完全取决于所使用的操作系统和计算机。在我的机器上,清单6.5中的输出可能是两个线程在两个CPU内核上并行运行的结果。而清单6.6中的输出是第一个线程在第二个线程启动之前完成的结果。您的系统可能会显示完全不同的结果图6.3显示了第一组和第二组结果的执行情况。
图6.3.清单6.4的两种可能执行
使用线程模块创建的线程相当耗费资源。它们消耗大量内存,因此您不应该创建大量的内存,因为这样做效率很低。如果您希望完全控制应用程序正在使用的线程,那么它们很有用,但在大多数使用情况下,线程池模块更优越。让我们看看线程池模块现在是如何工作的。
6.2.2 使用线程池
使用多线程的主要目的是代码的并行化。CPU密集型计算应尽可能多地使用CPU算力,这包括使用具有多核CPU的系统中所有内核的算力。
单个线程可以利用单个CPU内核的功能。因此,为了利用所有内核的功能,您可以简单地为每个内核创建一个线程。最大的问题是确保这些线程都很忙。您可能有100个任务,这些任务并不都需要相同的时间来完成,在线程之间分发它们并不简单。
或者,可以为每个任务创建一个线程。但这本身也有问题,其中之一是线程创建非常昂贵。大量线程将消耗大量内存。
什么是线程池
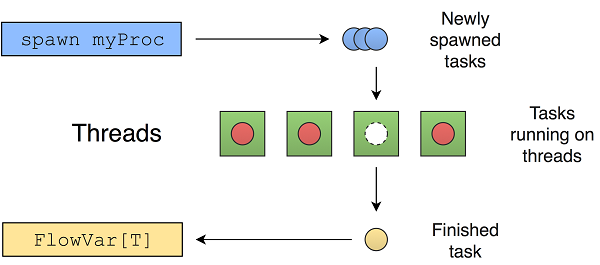
threadpool 线程池模块实现了一个抽象,它管理多个线程上的任务分配。线程本身也由线程池管理。
spawn 过程允许以过程的形式将任务添加到线程池中。线程池在其管理的一个线程中执行给定的过程。它确保程序使所有线程保持忙碌状态,从而以最佳方式利用CPU的功率图6.4显示了线程池如何在后台管理任务。
图6.4.Nim线程池
使用 spawn ``
spawn 过程接受表达式。在大多数情况下,表达式是过程调用 Spawn 返回类型为 FlowVar[T] 的值,该值保存所调用过程的返回值。与线程不能返回任何值的 threads 模块相比,这是一个优势。
清单6.7显示了相当于清单6.4中代码的派生。
清单6.7.使用 spawn 执行多个线程
import threadpool # <1>
var data = "Hello World"
proc countData(param: string) = # <2>
for i in 0 .. <param.len:
stdout.write($i)
echo()
spawn countData(data) # <3>
spawn countData(data)
sync() # <4>
<1> 需要显式导入线程池模块才能使用
spwan。<2> 传递给派生的过程不需要{.thread.}编译指示。
<3> spwan 过程的语法要简单得多。
<4>
sync过程用于等待所有派生过程完成。
将清单6.7中的代码保存为 listing4.nim ,然后编译并运行它。请记住,仍然需要指定 --threads:on 标志。输出应与清单6.5和6.6中所示的输出大致相同。
使用 spawn 执行的过程也必须是GC安全的。
正在从 FlowVar 类型检索返回值
让我们看一个示例,它显示了如何从派生过程中检索返回值。这涉及处理 FlowVar[T] 类型。这种类型可以被认为是一种容器,类似于您在第3章中使用的 Future[T] 类型。起初,容器内没有任何内容。当派生过程在单独的线程中执行时,在将来的某个时刻,它会返回一个值。发生这种情况时,返回的值被放入 FlowVar 容器中。
清单6.8显示了第3章中的 readLine 过程,其中有一个while循环,用于从终端读取文本而不阻塞。
清单6.8.使用 spwan 从终端读取输入
import threadpool, os # <1>
let lineFlowVar = spawn stdin.readLine() # <2>
while not lineFlowVar.isReady: # <3>
echo("No input received.") # <4>
echo("Will check again in 5 seconds.") # <4>
sleep(5000) # <4>
echo("Input received: ", ^lineFlowVar) # <6>
<1>
spwan需要导入threadpool模块。os模块定义sleep过程。<2> 将
readLine过程添加到线程池中,spawn将返回一个FlowVar[string]类型,该类型将分配给lineFlowVar变量。<3> 循环直到
lineFlowVar包含readLine返回的字符串值。<4> 显示有关程序正在执行的操作的一些状态消息。
<5> 暂停主线程5秒,
sleep参数以毫秒为单位。<6> 当循环完成时,可以使用
^运算符立即读取lineFlowVar。该行显示由readLine读取的输入。
将清单6.8保存为 listing5.nim ,然后编译并运行它。应用程序将等待您向终端输入一些输入。它只会每隔5秒检查输入是否已输入。
使用 FlowVar 类型很简单。读取包含在其中的值是使用 ^ 运算符完成的,请记住,使用此运算符将阻塞它所使用的线程,直到调用它的 FlowVar 包含值为止。您可以使用 isReady 过程检查 FlowVar 是否包含值。清单6.8检查 lineFlowVar 变量是否每隔5秒周期性地包含一个值。
请记住,清单6.8旨在演示 FlowVar[T] 是如何工作的。该示例并不实用,因为程序仅每5秒检查一次输入。
当然,在这种情况下,您也可以在主线程上调用 readLine ,因为它主线程上没有运行任何其他程序。这样做的目的是用一些其他过程替换 sleep(5000) 语句,这些过程在主线程中做一些有用的工作,例如,您可以绘制应用程序的用户界面,或调用异步I/O事件循环的 poll 过程,如第3章所示。
6.2.3 线程异常
异常在单独线程中的行为方式可能令人惊讶。当线程因未处理的异常而崩溃时,应用程序将随之崩溃。无论是否读取 FlowVar 的值都无关紧要,清单6.9显示了这种行为。
清单6.9.spawn过程中的异常。
import threadpool
proc crash(): string =
raise newException(Exception, "Crash")
let lineFlowVar = spawn crash()
sync()
将清单6.9保存为 listing6.nim ,然后编译并运行它。您应该在输出中看到一个回溯,指向 crash 过程中的 raise 语句。
提示
raise编译指示*{.raises.}编译指示可用于确保线程处理所有异常。要使用它,可以定义crash过程,如下所示:proc crash() :string {.raises:[].} = …
- traceback:回溯,追溯,可以查看错误代码的位置。
总之,向派生过程传递参数和接收过程结果的简单性,使 spawn 派生适用于运行时间相对较短的任务。这样的任务通常在执行结束时产生结果,因此在执行停止之前不需要与其他线程通信。
对于需要定期与其他线程通信的长时间运行的任务,应改用线程 threads 模块中定义的 createThread 过程。
[19] http://nim-lang.org/docs/threads.html [20] http://nim-lang.org/docs/threadpool.html
6.3 解析数据
既然您知道了如何在Nim中使用线程,那么让我们来看一个如何使用线程的实际示例。本节所示的示例将涉及解析器。
解析器可以从并行化中受益匪浅,因为它能够利用所有CPU内核,从而更高效地解析数据。因此,除了了解解析器如何工作外,本节还将向您展示并行化的实际用例,更重要的是,如何在这种用例中利用Nim的并发性和并行性特性。
每天都会产生大量数据;这些数据来自许多不同的来源,并用于许多不同的应用。计算机是处理数据的非常有用的工具。但为了使用这些数据,计算机必须理解数据存储的格式。
解析器是软件的一个组件,它接收输入数据并从中构建数据结构。数据通常是文本形式。在第3章中,您已经了解了JSON数据格式,以及如何使用 json 模块将其解析为数据结构,然后可以查询该数据结构以获取特定信息。
经常会遇到为简单数据格式编写自定义解析器的任务。Nim有很多方法可以解决这一问题。
在本节中,我将向您展示如何为维基百科的页面视图数据编写解析器。[21] 这些数据对许多不同的应用程序都很有用,但本节的目的是创建一个应用程序,该应用程序将在英语维基 百科中找到最受欢迎的页面。在本节中,您将:
- 了解维基百科页面计数文件的结构和格式。
- 使用不同的技术为页计数格式编写解析器。
- 通过将大文件拆分成大小方便的小块或片段来读取大文件。
[备注] 维基百科API 维基百科最近推出了一个Pageview API[22],它补充了原始页面视图数据。这个API使查找英语维基百科中最受欢迎的页面变得更加容易。如果您正在编写一个应用程序,需要专门查找维基百科上最受欢迎的页面,那么您可能需要使用API。手动解析原始数据的效率较低,但您希望发现该示例适用于其他任务。 在本节末尾,我还将向您展示如何并行化解析器。这将使它在具有多核CPU的系统上表现得更好。
6.3.1 了解维基百科页面计数格式
原始页面计数数据可以从以下URL下载:https://dumps.wikimedia.org/other/pagecounts-all-sites/。
数据文件被组织成特定的年份和月份。例如,2016年1月的页面计数数据可从以下URL获得:https://dumps.wikimedia.org/other/pagecounts-all-sites/2016/2016-01/. 然后,页面计数数据被进一步细分为一天和一小时。位于上述URL中的每个文件表示一小时内的访问者。这些文件都是gzip的,以减小它们的大小。
下载以下文件,然后解压缩:https://dumps.wikimedia.org/other/pagecounts-all-sites/2016/2016-01/pagecounts-20160101-050000.gz
Windows用户注意 在Windows上,您可能需要安装7zip或其他应用程序来提取gzip存档 该文件可能需要一段时间才能下载,具体取决于您的网速。这个文件在提取之前大约是92MB,提取之后大约是428MB,所以它是一个相当大的文件。解析器需要尽可能高效,以便及时解析该文件。 文件由换行符分隔的文本行填充,每行文本由以下4个空格分隔的字段组成:
domain_code page_title count_views total_response_size
domain_code 包含缩写域名,例如 en.wikipedia.org 缩写为 en 。 page_title 包含请求页面的标题,例如 Dublin 表示 http://en.wikipedia.org/wiki/Dublin 。 count_views 包含一小时内查看页面的次数。最后, total_response_size 包含页面请求引起的总响应大小。
例如,下面的行:
en Nim_(programming_language) 1 70231
表示有1个请求"http://en.wikipedia.org/wiki/Nim\_(programming\_language)",总共响应请求返回了70231个字节。
你下载的文件是一月份的小文件之一。它包含从2016年1月1日下午4:00 UTC到2016年1月份1日下午5:00 UTC在维基百科上访问的页面的数据。
6.3.2解析维基百科页面计数格式
在解析上述数据格式时,有许多不同的选项。在本小节中,我将使用两种不同的方法实现解析器:正则表达式和 parseutils 模块。
使用正则表达式
解析数据的常用方法是使用正则表达式。如果您曾经以任何方式处理过字符串处理,那么很可能遇到过它们。正则表达式非常流行,在许多情况下,当开发人员面临需要他们解析字符串的任务时,他们会立即使用正则表达式。
正则表达式决不是每个解析问题的神奇解决方案。例如,编写正则表达式来解析任意HTML实际上是不可能的。但是对于解析上面定义的简单数据格式的任务,正则表达式工作得很好。
深入解释正则表达式超出了本章的范围。如果你不熟悉它们,我们鼓励你在网上阅读它们。
Nim通过 re 模块支持正则表达式。它定义了使用正则表达式解析和操作字符串的过程和类型。
[注意] 外部依赖性
re模块是一个不纯的模块,这意味着它依赖于外部C库。 在re的情况下,库称为PCRE,它必须安装在应用程序旁边,以便应用程序正常运行。
让我们先来分析一行。清单6.10显示了如何使用 re 模块实现这一点。
清单6.10.使用 re 模块分析数据
import re # <1>
let pattern = re"([^\s]+)\s([^\s]+)\s(\d+)\s(\d+)" # <2>
var line = "en Nim_(programming_language) 1 70231"
var matches: array[4, string] # <3>
let start = find(line, pattern, matches) # <4>
doAssert start == 0 # <4>
doAssert matches[0] == "en" # <6>
doAssert matches[1] == "Nim_(programming_language)" # <6>
doAssert matches[2] == "1" # <6>
doAssert matches[3] == "70231" # <6>
echo("Parsed successsfully!")
<1>
re模块定义了下面使用的find过程<2> 使用
re构造过程构造新的正则表达式模式<3> 此
matches数组将保存line的匹配子字符串<4>
find过程用于查找正则表达式中子组指定的匹配子字符串。子字符串被放入matches数组中<5> 返回值表示匹配字符串的起始位置,如果没有匹配,则返回
-1<6> 第一个匹配组将捕获子字符串
en,然后是第二个匹配组,它将捕获Nim_(programming ing_language),依此类推警告
re构造过程 构造正则表达式是一项昂贵的操作,当使用同一正则表达式执行多个正则表达式匹配时,请确保重用re构造过程返回的值
将清单6.10另存为 listing7.nim ,然后编译并运行它。程序应能成功编译并运行。程序应显示解析成功!。
提示 PCRE 问题 如果程序退出时出现类似无法加载:pcre.dll的错误,则您缺少pcre库,必须安装它。
用正则表达式解析字符串的代码很简单。只要您知道如何创建正则表达式,使用它应该不会有任何问题。
re 模块还包括用于解析和操作字符串的其他过程。例如,可以使用 replace 过程替换匹配的子字符串。请查看 re 模块的文档以了解更多信息。[23]
使用 split 拆分手动分析数据 ``
您还可以用许多不同的方式手动解析数据。这有多种优点,但也有一些缺点。与使用正则表达式相比,最大的优点是您的应用程序不依赖PCRE库。手动解析还可以让您更精确地控制解析过程。在某些情况下,最大的缺点是手动解析数据需要更多的代码。
对于这样一种简单的数据格式,您可以使用 strutils 模块中定义的 split 过程。清单6.11显示了如何使用 split 解析 en Nim_(programming_language) 1 70231 。
清单6.11.使用split进行分析
import strutils # <1>
var line = "en Nim_(programming_language) 1 70231"
var matches = line.split() # <2>
doAssert matches[0] == "en" # <3>
doAssert matches[1] == "Nim_(programming_language)" # <3>
doAssert matches[2] == "1" # <3>
doAssert matches[3] == "70231" # <3>
<1>
strutils模块定义split过程<2> 默认情况下,
split过程在找到空格时拆分字符串。返回的序列将是@["en", "Nim_(programming_language)", "1", "70231"]<3> 生成的
matches变量的内容与之前相同
这将非常适合这个用例。但对于更复杂的数据格式,您可能希望使用更灵活的格式。解析字符串最灵活的方法是使用while循环遍历字符串中的每个字符。这种解析方法也非常冗长,但在某些情况下非常有用,例如在解析更复杂的数据格式(如HTML)时。Nim提供了一个 parseutils 模块,该模块定义了使用此类方法进行解析的过程。
使用 parseutils 手动分析数据 ``
清单6.12显示了如何使用 parserutils 解析 "en Nim_(programming_language) 1 70231"。
清单6.12.使用 parseutils 进行分析
import parseutils # <1>
var line = "en Nim_(programming_language) 1 70231"
var i = 0 # <2>
var domainCode = "" # <3>
i.inc parseUntil(line, domainCode, {' '}, i) # <4>
i.inc # <6>
var pageTitle = "" # <3>
i.inc parseUntil(line, pageTitle, {' '}, i) # <4>
i.inc # <6>
var countViews = 0 # <3>
i.inc parseInt(line, countViews, i) # <4>
i.inc # <6>
var totalSize = 0 # <3>
i.inc parseInt(line, totalSize, i) # <4>
doAssert domainCode == "en"
doAssert pageTitle == "Nim_(programming_language)"
doAssert countViews == 1
doAssert totalSize == 70231
<1>导入定义
parseUntil的parseutils<2> 定义一个计数器,以跟踪程序当前在字符串中的位置
<3> 定义一个字符串或int变量,用于存储解析的令牌
<4> 将从索引
i开始的字符从字符串line复制到第二个参数中指定的字符串,直到line[i]==。返回的值是捕获的字符数<5> 分析字符串
line中从索引i开始的int。解析的int存储在第二个参数中。返回值是捕获的字符数<6> 通过简单地递增
i来跳过空白字符
清单6.12中的代码比前一个清单复杂得多,但允许更大的灵活性。 parseutils 模块定义了许多其他对解析有用的过程。它们大多只是while循环的方便包装。例如, i.inc parseUntil(line, domainCode, {' '}, i) 的等效代码如下:
while line[i] != ' ':
domainCode.add(line[i])
i.inc
由于此解析器的灵活性,代码能够在一个步骤中将最后两个字段解析为整数。而不是必须首先分离字段,然后单独解析整数,这将是低效的。
总之, split 过程看起来是所有过程中最简单的,但实际上比 parseutils 慢。这是因为它需要创建一个序列和新字符串来保存匹配项。相比之下,使用 parseutils 的解析代码只需要创建2个新字符串和2个新整数,就不会产生与创建序列相关的开销。
正则表达式解析代码也更简单,但它受到PCRE依赖性的影响,并且比 parseutils 解析器慢。
这使得 parserutils 解析器最适合这个用例,尽管它稍微复杂一些,而且非常冗长。当分析 pagecounts-20160101-050000 文件中包含的7156099行时,它的速度将非常方便。
6.3.3 有效处理文件的每一行
维基百科的页面计数文件很大。每一个大小约为500MB,包含约1000万行数据。我要求您下载的 pagecounts-20160101-050000 大小为428MB,包含7156099行页计数数据。它是一月份最小的之一,我选择它是为了节省一些带宽。
为了有效地解析该文件,您需要以片段形式使用该文件。将整个文件读入程序的内存将消耗至少428MB的RAM,由于各种开销,实际消耗可能会更大。这就是为什么通过将大文件分解成大小方便的小片段(也称为块)来读取大文件是一个好主意。
使用迭代器以片段形式读取文件
Nim定义了一个迭代器,它在文件中的每一行上迭代。这个迭代器不需要将整个文件的内容复制到程序的内存中,这使得它非常高效。迭代器称为行 line ,在 system 模块中定义。
清单6.13显示了如何使用 line 行迭代器从 pagecounts-20160101-050000 文件中读取行。
清单6.13.在文件中的每一行上迭代
import os # <1>
proc readPageCounts(filename: string) = # <2>
for line in filename.lines: # <3>
echo(line) # <4>
when isMainModule: # <4>
const file = "pagecounts-20160101-050000" # <6>
let filename = getCurrentDir() / file # <7>
readPageCounts(filename) # <8>
<1>
os模块定义getCurrentDir过程<2> 定义以页计数文件的文件名为参数的
readPageCounts过程<3> 使用
lines迭代器遍历位于filename的文件中的每一行<4> 显示读取的每一行
<5> 检查此模块是否正在编译为主模块
<6> 定义一个常量
file,并为其指定页计数文件的名称<7> 定义变量
filename,并为其指定与file连接的程序当前工作目录的路径。/运算符在os模块中定义,用于连接文件路径。<8> 调用
readPageCounts过程,并将变量filename的值作为参数传递。
将清单6.13保存为 sequential_counts.nim ,然后编译并运行它。该程序将花费大约一分钟的时间来执行,因为它将显示页面计数文件的每一行。您可以通过同时按下Control和C键来终止它。当它运行时,你可以观察到内存使用情况,它应该保持在低位。
分析每行
现在,您可以简单地将上一节的解析代码添加到清单6.13中的代码中。清单6.14显示了解析器如何集成到清单6.1-3中,更改以粗体突出显示。
清单6.14.解析文件中的每一行
import os, parseutils
proc parse(line: string, domainCode, pageTitle: var string,
countViews, totalSize: var int) = # <1>
var i = 0
domainCode.setLen(0) # <2>
i.inc parseUntil(line, domainCode, {' '}, i)
i.inc
pageTitle.setLen(0) # <2>
i.inc parseUntil(line, pageTitle, {' '}, i)
i.inc
countViews = 0 # <3>
i.inc parseInt(line, countViews, i)
i.inc
totalSize = 0 # <3>
i.inc parseInt(line, totalSize, i)
proc readPageCounts(filename: string) =
var domainCode = ""
var pageTitle = ""
var countViews = 0
var totalSize = 0
for line in filename.lines:
parse(line, domainCode, pageTitle, countViews, totalSize) # <4>
echo("Title: ", pageTitle) # <4>
when isMainModule:
const file = "pagecounts-20160101-050000"
let filename = getCurrentDir() / file
readPageCounts(filename)
<1> 存储解析令牌的变量通过引用传递,这更有效,因为不必为每个
parse调用分配新字符串<2> 字符串的长度重置为0。这比分配``要有效得多,因为这会分配一个新字符串
<3> 整数变量简单地重置为0
<4> 调用
parse过程,并将其与可以存储令牌的变量一起传递到当前的line<5> 显示页面计数文件中找到的每个页面的标题
将 sequential_counts.nim 中的代码替换为清单6.14中的代码。清单6.15显示了 sequeential_counts.nim 的一些输出可能是什么样子。
清单6.15. sequential_counts.nim 的输出
...
Title: List_of_digital_terrestrial_television_channels_(UK)
Title: List_of_diglossic_regions
Title: List_of_dignitaries_at_the_state_funeral_of_John_F._Kennedy
Title: List_of_dimensionless_quantities
Title: List_of_diners
Title: List_of_dinosaur_genera
Title: List_of_dinosaur_specimens_with_nicknames
Title: List_of_dinosaurs
...
该代码采用了许多优化。通常,Nim应用程序中最大的速度下降是由于分配和释放了太多变量。 parse 过程可以返回解析的令牌,但这将导致每次迭代都分配一个新字符串。相反, parse 过程接受对2个字符串和2个 int 的可变引用,然后用解析的令牌填充。对于不进行优化而需要9.3秒完成的输入,完成优化需要7.8秒。相差1.5秒。使用 setLen 是另一种优化,它确保字符串不会被重新分配,而是被重用。 parse 过程至少执行了700万次,因此任何微小的优化都会大大提高总执行速度。
本书稍后将介绍的探查器可以向您展示程序中经常执行的过程。然后,您可以使用类似于此处所述的优化。
查找最受欢迎的文章
既然解析代码已经引入,剩下的就是找到英语维基百科上最流行的文章清单6.16显示了已完成的 sequential_counts 应用程序,最新的更改以粗体显示。
清单6.16.完成的 sequential_counts.nim
import os, parseutils
proc parse(line: string, domainCode, pageTitle: var string,
countViews, totalSize: var int) =
var i = 0
domainCode.setLen(0)
i.inc parseUntil(line, domainCode, {' '}, i)
i.inc
pageTitle.setLen(0)
i.inc parseUntil(line, pageTitle, {' '}, i)
i.inc
countViews = 0
i.inc parseInt(line, countViews, i)
i.inc
totalSize = 0
i.inc parseInt(line, totalSize, i)
proc readPageCounts(filename: string) =
var domainCode = ""
var pageTitle = ""
var countViews = 0
var totalSize = 0
**var mostPopular = ("", "", 0, 0)** # <1>
for line in filename.lines:
parse(line, domainCode, pageTitle, countViews, totalSize)
**if domainCode == "en" and countViews > mostPopular[2]:** # <2>
**mostPopular = (domainCode, pageTitle, countViews, totalSize)** # <3>
**echo("Most popular is: ", mostPopular)**
when isMainModule:
const file = "pagecounts-20160101-050000"
let filename = getCurrentDir() / file
readPageCounts(filename)
<1> 定义一个变量来保存有关最受欢迎页面的信息。这被定义为存储4个解析字段的元组
<2> 检查当前行是否包含来自英语维基百科的页面信息,以及其浏览次数是否大于当前最受欢迎的页面
<3> 如果是,则将其保存为最受欢迎的新页面
用清单6.16中的代码替换 sequential_counts.nim 的内容,然后在发布模式下编译并运行它。几秒钟后,您将看到类似于清单6.17中的输出。
[注意] 发布模式 通过将
-d:release标志传递给nim编译器,确保在发布模式下编译sequential_counts.nim。如果没有该标志,应用程序的执行时间将大大增加。
清单6.17.sequential_counts.nim的输出
Most popular is: ("en", "Main_Page", 271165, 4791147476)
并非 Most popular is: (Field0: en, Field1: Main_Page, Field2: 271165, Field3: 4791147476)
英语维基百科中最受欢迎的页面实际上是主页!这很有道理,虽然事后看来很明显,但编辑您编写的代码以查找更有趣的统计数据是很简单的。我现在挑战您编辑 sequential_counts.nim 并摆弄数据。你可以尝试查找英语维基百科中最受欢迎的前10个页面,也可以下载不同的页面计数文件并比较结果。
现在您应该对如何有效地解析数据有了一个好主意。您将了解在Nim应用程序中要注意哪些瓶颈,以及如何解决这些瓶颈。下一步是将这个解析器并行化,以便在多核CPU上它的执行时间更少。
[21] https://wikitech.wikimedia.org/wiki/Analytics/Data/Pagecounts-all-sites
[22] https://wikitech.wikimedia.org/wiki/Analytics/PageviewAPI
[23] http://nim-lang.org/docs/re.html
6.4 并行化解析器
为了使程序并行,它必须使用线程。如前所述,有两种方法可以在Nim中创建线程。使用 threads 线程模块或使用 threadpool 线程池模块。两者都可以工作,但线程池模块更适合此程序。
6.4.1测量顺序计数的执行时间
在开始并行化代码之前,让我们测量执行 sequential_counts 需要多长时间。
这可以在类Unix操作系统上通过使用 time 命令非常容易地完成。正在执行 time/sequential_counts 应输出sequential _counts的执行时间。在配备SSD和双核2.7GHz Intel core i5 CPU(包括超线程)的Macbook Pro上,执行时间约为2.8秒。
在Windows上,您需要打开一个新的Windows PowerShell窗口,然后使用 Measure-Command 命令测量执行时间。执行 Measure-Command {./sequential_counts.exe}应输出 sequential_counts 的执行时间。
该程序目前在一个线程中运行,非常占用CPU。这意味着通过使其并行,可以显著提高其速度。
6.4.2 并行化顺序计数
将 sequeential_counts.nim 复制到 parallel_counts.nim 。这将是一个很快就会变为并行的文件。
那么应该如何使用线程池 threadpool 模块来并行化这些代码呢?您可能会尝试 spawn parse 过程,但这无法工作,因为它需要无法安全传递给派生过程的 var 参数。它也没有太大帮助,因为对 parse 的单个调用相对较快。
在并行化此代码之前,必须首先更改读取页计数文件的方式。不需要单独读取每一行,而是需要以大片段读取文件。像这样读取文件时需要考虑一些因素,其中之一是要读取的片段大小。
考虑以下场景。页面计数文件以以下内容开头:
en Main_Page 123 1234567
en Nim_(programming_language) 100 12415551
如果片段大小太小,仅读取 en-Main_Page ,则程序将失败,因为片段大小不足。为了解决这个问题,片段大小需要足够大。
另一个问题是,在大多数情况下,片段开头将包含有效数据,但结尾将是未完全读取的行!例如en-MainPage 123 1234567\nen Nim。每次出现 \n (新行)后,都需要拆分此数据,并且需要分别分析每一行。最后一行将导致错误,因为它未满。解决方案是找到最后一行的结尾,然后将尚未完全读取的行的解析推迟到下次读取文件片段时。
下面是 parallel_counts.nim 的工作原理:
- 应该阅读一大块文本,而不是阅读行。
- 应创建名为
parseChunk的新过程。*parseChunk过程应该接收一段文本,遍历每一行并将其传递给parse过程。 - 同时,它应该检查哪些已解析的页面最受欢迎。
- 应派生
parseChunk过程。片段的slice应传递给parseChunk,该片段不应包含任何不完整的行。 - 应保存不完整的行。一旦读取了下一个片段,就应该在新准备好的片段之前添加不完整的行。
注释 术语 术语chunk与术语fragment同义,在本章中,两者将互换使用 清单6.18、清单6.19和清单6.20显示了
parallel_counts.nim文件的不同部分,其实现与上述类似。
6.4.3 类型定义和解析过程
清单6.18从文件顶部开始,其中没有太多更改。这包括import语句、一些新的类型定义和原始的 parse 过程。定义了一个新的 Stats 类型来存储特定页面的页面计数统计信息,该类型将用于存储每个派生过程中最受欢迎的页面。 Stats 类型将从派生过程返回,这意味着它必须是 ref 类型,因为派生当前无法派生返回自定义值类型的过程。还定义了一个名为 newStats 的新过程,它只是构造一个新的空 Stats 对象。此外,还有 $ 的定义,它将 Stats 类型简单地转换为字符串。
清单6.18.parallel_counts.nim的顶部
import os, parseutils, threadpool, strutils # <1>
type
Stats = ref object # <2>
domainCode, pageTitle: string # <3>
countViews, totalSize: int # <3>
proc newStats(): Stats = # <4>
Stats(domainCode: "", pageTitle: "", countViews: 0, totalSize: 0)
proc `$`(stats: Stats): string = # <4>
"(domainCode: $#, pageTitle: $#, countViews: $#, totalSize: $#)" % [
stats.domainCode, stats.pageTitle, $stats.countViews, $stats.totalSize
]
proc parse(line: string, domainCode, pageTitle: var string,
countViews, totalSize: var int) = # <6>
if line.len == 0: return
var i = 0
domainCode.setLen(0)
i.inc parseUntil(line, domainCode, {' '}, i)
i.inc
pageTitle.setLen(0)
i.inc parseUntil(line, pageTitle, {' '}, i)
i.inc
countViews = 0
i.inc parseInt(line, countViews, i)
i.inc
totalSize = 0
i.inc parseInt(line, totalSize, i)
<1>
spawn需要threadpool``线程池模块,%运算符需要strutils``结构模块<2> 定义一个新的
Stats类型,它将保存有关页面统计信息的信息。该类型必须定义为引用ref,因为无法派生返回非ref类型的过程。<3>
Stats类型为每个解析的令牌定义字段。<4> 定义一个名为
newStats的新过程,它充当`Stats类型的构造过程。<5> 为
Stats类型定义一个$运算符,以便轻松将其转换为字符串。实际上,这意味着echo可以显示它。<6>
parse过程相同。
6.4.4 parseChunk 过程
清单6.19显示了 parallel_counts.nim 文件的中间部分。它定义了一个名为 parseChunk 的新过程,该过程接受名为 chunk 的字符串参数,并返回该片段中最流行的英语维基百科页面。该片段由多行页计数数据组成。该过程首先初始化 result 变量,返回类型是 ref 类型,必须进行初始化,使其不是 nil 。该过程的其余部分与 sequential_counts.nim 文件中的 readPageCounts 过程类似。它定义了4个变量来存储解析的令牌,然后使用 splitLines 迭代器遍历 chunk 中的行,并解析每一行。
清单6.19.parallel_counts.nim的中间部分
proc parseChunk(chunk: string): Stats = # <1>
result = newStats() # <2>
var domainCode = "" # <3>
var pageTitle = "" # <3>
var countViews = 0 # <3>
var totalSize = 0 # <3>
for line in splitLines(chunk): # <4>
parse(line, domainCode, pageTitle, countViews, totalSize) # <4>
if domainCode == "en" and countViews > result.countViews: # <6>
result = Stats(domainCode: domainCode, pageTitle: pageTitle, # <7>
countViews: countViews, totalSize: totalSize)
<1>
parseChunk过程与sequential_counts.nim中的readPageCounts过程非常相似。<2> 用
Stats类型的新值初始化result变量。<3> 创建变量以存储解析的令牌。
<4> 在
chunk中的每一行上重复。<5> 在
chunk内的每一行调用parse过程,将其解析为4个字段:domainCode、pageTitle、countViews和totalSize。<6> 检查解析的页面是否在英语维基百科中,以及它是否获得了比存储在
result中的页面更多的浏览量。<7> 如果是这种情况,则将
result分配给已解析的页面。
6.4.5 并行 readPageCounts 过程
清单6.20显示了 readPageCounts 过程,自上次在清单6.16中看到它以来,该过程已进行了大量修改。现在它接受了一个名为 chunkSize 的可选参数,该参数决定每次迭代应该读取多少字符。该过程的实现是最不同的,文件是使用打开过程手动打开的,以下是正确存储片段读取过程结果所需的变量定义。
片段读取过程由于代码需要确保跟踪未完成的行而变得复杂。它通过向后移动缓冲区的内容来实现,缓冲区临时存储片段,直到找到换行符。然后,将缓冲区字符串从片段的开头分段到片段中最后一行的结尾。然后将生成的切片传递给 parseChunk 过程,该过程使用 spawn 派生在新线程中派生。
然后将尚未解析的片段的结尾移动到缓冲区的开头。在下一次迭代中,将读取的字符长度将为 chunkSize 减去上一次迭代未读取的缓冲区长度。
清单6.20. parallel_counts.nim 的底部
proc readPageCounts(filename: string, chunkSize = 1_000_000) = # <1>
var file = open(filename) # <2>
var responses = newSeq[FlowVar[Stats]]() # <3>
var buffer = newString(chunkSize) # <4>
var oldBufferLen = 0 # <4>
while not endOfFile(file): # <6>
let reqSize = chunksize - oldBufferLen # <7>
let readSize = file.readChars(buffer, oldBufferLen, reqSize) + oldBufferLen # <8>
var chunkLen = readSize # <9>
while chunkLen >= 0 and buffer[chunkLen - 1] notin NewLines: # <10>
chunkLen.dec
responses.add(spawn parseChunk(buffer[0 .. <chunkLen])) # <11>
oldBufferLen = readSize - chunkLen
buffer[0 .. <oldBufferLen] = buffer[readSize - oldBufferLen .. ^1] # <12>
var mostPopular = newStats()
for resp in responses: # <13>
let statistic = ^resp # <14>
if statistic.countViews > mostPopular.countViews: # <15>
mostPopular = statistic
echo("Most popular is: ", mostPopular)
file.close() # <16>
when isMainModule:
const file = "pagecounts-20160101-050000"
let filename = getCurrentDir() / file
readPageCounts(filename)
<1>
readPageCounts过程现在包含默认值为1_000_000的chunkSize参数。下划线有助于可读性,Nim忽略了下划线。<2>
open过程现在用于打开文件,它返回存储在file变量中的file对象。<3> 定义一个新的响应序列,以保存将由派生返回的
FlowVar对象。<4> 定义长度等于
chunkSize的新缓冲区字符串。碎片将存储在这里。<5> 定义一个变量来存储未解析的最后一个缓冲区的长度。
<6> 循环,直到读取完整文件。
<7> 计算需要读取的字符数。
<8> 使用
readChars过程读取reqSize数量的字符。此过程将从oldBufferLen开始放置读取的字符,这将确保不会覆盖旧缓冲区。添加oldBufferLen是因为它是先前读取的旧缓冲区的长度。<9> 创建一个变量来存储要解析的片段长度。
<10> 减小
chunkLen、变量,直到chunkLen-1指向任何换行符。<11> 创建一个新线程来执行
parseChunk过程,传递一个包含可解析片段的缓冲区片段。将派生返回的FlowVar[string]添加到响应列表中。<12> 将未解析的片段部分分配给缓冲区的开头。
<13> 遍历每个响应。
<14> 阻塞主线程,直到可以读取响应,然后将响应值保存在变量
statistics中。<15> 检查特定片段中最受欢迎的页面是否比保存在
mostPopular变量中的页面更受欢迎。如果是,则用它覆盖mostPopular变量。<16> 确保文件对象已关闭。
不幸的是,并行版本更复杂。复杂性主要局限于 readPageCounts 过程,其中以片段形式读取文件的算法会增加程序的复杂性。但就行数而言,并行版本的长度仅为其两倍。
6.4.6 parallel_counts 的执行时间
将清单6.18、清单6.19和清单6.20合并到一个 parallel_counts.nim 文件中。然后编译并运行程序。编译时,确保将 --threads:on 标志和 -d:release 标志传递给Nim。使用上述技术测量执行时间。
在配备SSD和双核2.7GHz Intel core i5 CPU(包括超线程)的Macbook Pro上,执行时间约为1.2秒,与顺序版本执行所需的2.8秒相比,执行时间减少了50%以上。这是一个很大的区别!
在类Unix系统上, time 命令允许我们通过查看其CPU使用情况来验证并行版本实际上是并行的。例如,/parallel_counts 4.30s用户0.25s系统364%cpu 1.251总计,这表明 parallel_count 使用了364%的可用cpu。相比之下, sequential_counts 几乎总是显示99%的CPU使用率。
既然您已经了解了如何并行化解析器,那么您应该对如何并行化Nim代码有了更好的了解。本章的最后一节将向您介绍竞争条件以及如何避免竞争条件。
6.5 应对竞争状态
在Nim中编写并发代码时,通常不需要担心竞争状态。由于Nim对GC安全过程的限制:属于另一个线程的内存不能在派生过程或使用{.thread.}编译标记的过程中访问。
当两个或多个线程同时尝试对共享资源进行读写时,会出现竞争使用状态。这种行为可能导致不可预测的结果,通常很难调试。这就是Nim阻止线程之间共享某些资源的原因之一。Nim更倾向于使用替代方法(如防止竞争状态的通道)共享数据。
有时这些方法不适合某些用例,例如当线程需要修改大量数据时。因为Nim还支持共享内存,所以只要您只想共享值类型,就可以通过全局变量共享内存。共享引用类型要困难得多,因为您必须使用Nim的手动内存管理过程。
[警告] 共享内存 使用共享内存是有风险的,因为它会增加代码中出现竞争状态的机会。再加上你必须自己管理内存这一事实,我建议你只有在你确定它是必需的,并且你知道自己在做什么时才使用它。
清单6.21实现了一个简单的程序,它在并行运行的两个线程中递增全局变量的值。结果是竞争状态。
清单6.21.共享内存的竞争状态情况
import threadpool # <1>
var counter = 0 # <2>
proc increment(x: int) =
for i in 0 .. <x: # <3>
var value = counter # <4>
value.inc # <4>
counter = value # <6>
spawn increment(10_000) # <7>
spawn increment(10_000) # <7>
sync() # <8>
echo(counter) # <9>
<1>
threadpool模块定义spawn过程。<2> 定义名为
counter的全局变量。<3> 从
0循环到x-1。<4> 定义一个名为
value的新局部变量,并为其赋值counter的值。<5> 增量
value。<6> 将全局
counter变量的值设置为value值。<7> 生成两个新线程,它们将以
10_000作为参数调用increment过程。<8> 等待所有线程完成。
<9> 显示计数器的值。
在这种情况下, increment 过程是GC安全的,因为它访问的全局变量 counter 的类型为 int ,这是一种值类型。 increment 过程将全局 counter 变量 x 的次数递增。该过程产生两次,这意味着将同时执行两个 increment 过程。事实上,它们都在读取、递增,然后以离散的步骤将递增的值写入全局 counter 变量,这意味着可能会丢失一些增量。
提示 共享必须在堆上分配的内存 值类型(如整数)可以存在于堆栈中(如果值存储在全局变量中,则存在于可执行文件的数据部分中),但引用类型(如
string、seq[T]和ref T)不能存在。Nim支持共享引用类型,但它不会为您管理内存。这在Nim的未来版本中可能会发生变化,但当前必须使用在system模块中定义的名为allocShared的过程手动分配共享内存第8章将对此进行更详细的解释。
将清单6.21保存为 race_condition.nim ,然后编译并运行它。运行几次并记录结果。结果应该是随机的,几乎永远不会显示 20000 的预期值图6.5显示了清单6.21的执行情况。
图6.5.清单6.21的同步和非同步执行
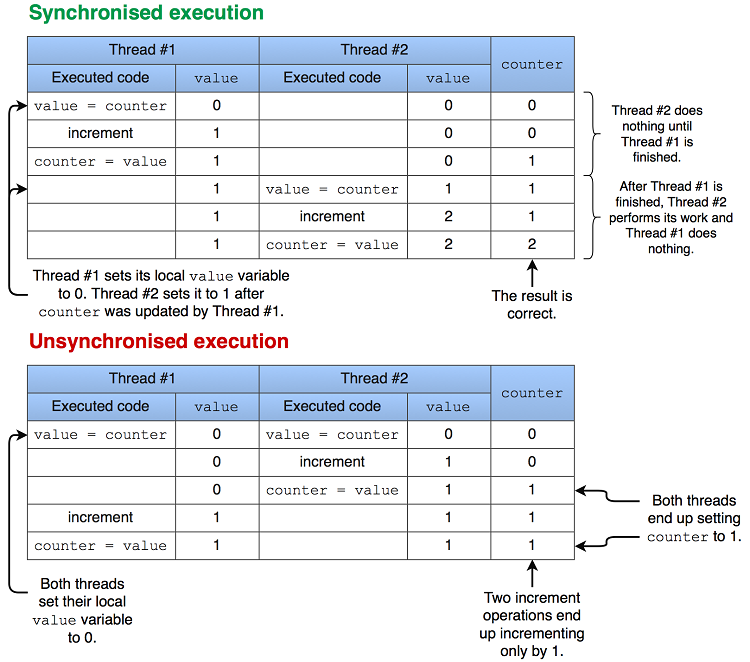
防止竞争状态非常重要,因为每当由于竞争状态而出现错误时,它几乎总是不确定的。这个bug将很难再现,一旦再现,调试就会变得更加困难,因为这样做可能会导致bug消失。
既然你知道了什么是种族状况,让我们来讨论一下如何防止它们。
6.5.1使用保护装置和锁防止竞争状态
与大多数语言一样,Nim提供了同步机制,以确保资源一次只能由单个线程使用。
其中一个机制是锁。它强制限制对资源的访问,并且通常与单个资源配对。在访问该资源之前,获取锁,在访问资源之后释放锁。尝试访问同一资源的其他线程必须尝试获取同一锁,如果另一个线程已经获取了该锁,则获取操作将阻止该线程,直到释放该锁。这确保只有一个线程可以访问资源。
锁工作得很好,但默认情况下不会分配给任何变量。可以使用守卫分配它们。当使用特定锁保护变量时,编译将确保在允许访问之前锁定该锁。任何其他访问都将导致编译时错误。
清单6.22显示了如何定义新的 Lock 和保护变量。
清单 6.22. unguarded_access.nim
import threadpool, locks # <1>
var counterLock: Lock # <2>
initLock(counterLock) # <3>
var counter {.guard: counterLock.} = 0 # <4>
proc increment(x: int) =
for i in 0 .. <x:
var value = counter
value.inc
counter = value
spawn increment(10_000)
spawn increment(10_000)
sync()
echo(counter)
<1>
locks模块现在已导入,它定义了Lock类型和相关过程。<2> 定义了类型为
Lock的新counterLock。<3> 使用
initLock过程初始化counterLock锁。<4> {.guard.} 编译指示用于确保
counter变量受counterLock锁保护。
将清单6.22另存为 unguared_access.nim ,然后对其进行编译。编译将失败,出现 unguarded_access.nim(9,17)error:unguarded-access:counter 。这是因为 counter 变量受到保护,该保护确保在 counterLock 锁被锁定后,必须对 counter 进行任何访问。让我们通过锁定 counterLock 锁来修复此错误。
清单6.23. parallel_incrementer.nim
import threadpool, locks
var counterLock: Lock
initLock(counterLock)
var counter {.guard: counterLock.} = 0
proc increment(x: int) =
for i in 0 .. <x:
withLock counterLock: # <1>
var value = counter
value.inc
counter = value
spawn increment(10_000)
spawn increment(10_000)
sync()
echo(counter)
<1> 访问 counter 变量的代码现在位于 withLock 部分中。这将锁定锁,并确保在部分下的代码结束后解锁。
将清单6.23中的代码保存为 parallel_incrementer.nim ,然后编译并运行它。该文件应编译成功,其输出应始终为 20000 ,这意味着竞争条件已修复!编译器验证每个受保护的变量是否被正确锁定,这一事实确保了代码的安全执行。它也有助于防止将来由于新代码或现有代码被更改而意外出现错误。
6.5.2使用通道 channels ,以便线程可以发送和接收消息
尽管Nim为了使锁尽可能安全而付出了所有努力,但它们可能并不总是最安全的选择。对于某些用例,它们可能是不合适的,例如当线程共享很少的资源时。通道提供了另一种同步形式,允许线程在彼此之间发送和接收消息。
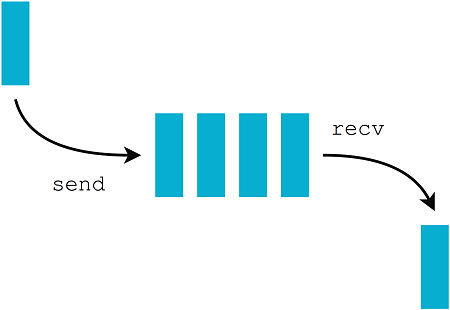
channels通道是queue队列的实现,即FIFO,先进先出数据结构。这意味着要添加到通道的第一个值将是要删除的第一个。可视化这种数据结构的最佳方式是想象自己在自助餐厅排队等候食物,第一个排队的人也是第一个拿到食物的人图6.6显示了FIFO通道的表示。
图6.6 FIFO通道的表示
Nim在标准库的 channels 模块中实现通道。此模块是 system 的一部分,因此不需要显式导入。通道被创建为全局变量,允许每个线程通过它发送和接收消息。一旦定义了通道,就必须使用 open 过程对其进行初始化。
清单6.24定义并初始化一个新的 chan 变量,类型为 Channel[string] 。可以在方括号内指定任何类型,包括您自己的自定义类型。
清单6.24.使用 open 初始化通道
var chan: Channel[string]
open(chan)
值可以使用 send 过程发送,也可以使用 recv 过程接收清单6.25显示了如何使用这两个过程。
清单6.25.通过通道发送和接收数据
import os, threadpool # <1>
var chan: Channel[string]
open(chan)
proc sayHello() =
sleep(1000) # <2>
chan.send("Hello!")
spawn sayHello() # <3>
doAssert chan.recv() == "Hello!" # <4>
<1>
os模块定义sleep过程。spawn需要threadpool模块。 <2> 在通过chan发送消息之前,sayHello过程将休眠线程1秒钟。 <3> 在另一个线程中执行sayHello过程。 <4> 阻塞主线程,直到收到 "Hello!"。
recv 过程将被阻止,直到收到消息。您可以使用 tryRecv 过程来获得非阻塞行为,它返回一个由布尔值组成的元组,该布尔值确定是否接收到数据,以及实际数据。
为了让您更好地了解通道的工作方式,让我向您展示如何使用通道而不是锁来实现清单6.23**下面的清单6.26显示了使用通道实现的 parallel_incrementer.nim 。
清单6.26.使用通道实现的 parallel_incrementer.nim
import threadpool
var resultChan: Channel[int] # <1>
open(resultChan) # <2>
proc increment(x: int) =
var counter = 0 # <3>
for i in 0 .. <x:
counter.inc
resultChan.send(counter) # <4>
spawn increment(10_000)
spawn increment(10_000)
sync() # <4>
var total = 0
for i in 0 .. <resultChan.peek: # <6>
total.inc resultChan.recv() # <7>
echo(total)
<1> 定义新的全局
Channel[int]变量。 <2> 初始化信道,以便通过它发送消息。 <3> 这一次,counter变量是increment过程的局部变量。 <4> 计数器计算完成后,其值将通过通道发送。 <5> 等待两个线程完成。。 <6>peek过程返回通道内等待读取的消息量。 <7> 读取其中一条消息,并按消息值增加total。
全局 counter 变量被全局 resultChan 通道替换。 increment 过程将本地 counter 变量 x 增加次数,然后通过通道发送 counter 的值。这是在两个不同的线程中完成的。
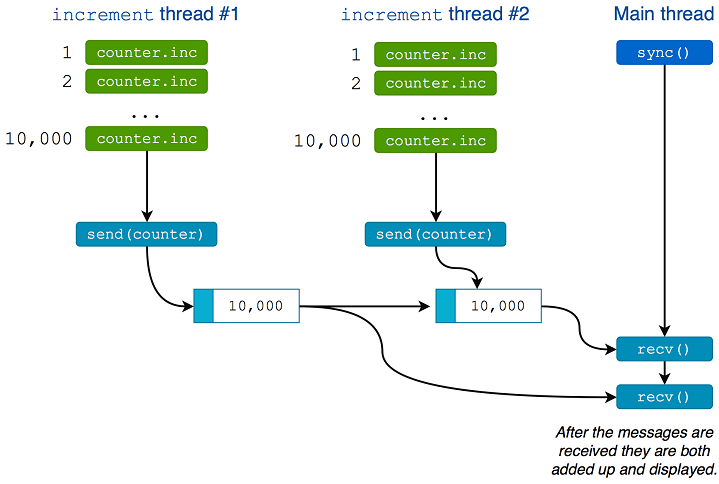
主线程等待两个线程完成,此时它读取已发送到 resultChan 的消息图6.7显示了清单6.26的执行。
图6.7清单6.26的执行
6.6 小结
本章介绍了Nim中的并发性。它解释了并发和并行之间的重要区别,展示了在Nim中创建线程的两种主要方法,并描述了Nim独特的线程模型。我们还讨论了解析,在Nim中进行解析的许多不同方法,以及并行解析的方法。 本章包括:
- 并发和并行之间的区别
- 使用
threads模块创建重量级线程。 - 使用
spawn派生和threadpool线程池模块创建轻量级线程。 - 线程中的GC安全性以及编译器如何强制执行它
- 使用正则表达式、
parseutils等进行分析。 - 解析器的并行化
- 使用锁和通道防止竞争状态。
下一章将提供实用信息,向您展示如何构建一个简单的Twitter克隆。您将在下一章中学习web开发,并了解Nim的许多不同方面,这些方面您还没有看到。